Does Google Really Use TF-IDF?
Using TF-IDF for content optimization is like getting tickets to the playoffs, only to realize you’re in the cheap seats with a blocked view and the Winnipeg Jets are playing. Proponents of TF-IDF are like Toronto Maple Leaf fans. While the Leafs may win an occasional game, it’s been 54 years since the one the Stanley Cup. Yet fans keep hoping.
TF-IDF isn’t an advanced concept. Term Frequency is a concept that was introduced in the 1950’s while Inverse Document Frequency appeared in the 1970’s. That’s about 50 years ago!
Nevertheless, TF-IDF does have its uses. Bill Slawski conducted a search of the USPTO.gov site and found that over 350 Google patents mention the concept. But TF-IDF is only a bit-player in an ensemble of algorithms and most people over-emphasize its role.
If you really want to know where the puck is going, read this Google Research paper, Rethinking Search: Making Experts out of Dilettantes by Metzler, Tay, Bahri, and Najork, published May 2021.
In this paper, the authors mention TF-IDF in relation to “current state-of-the-art retrieval systems.” Spoiler alert TF-IDF fans! You’re in for a disappointment.
There are “three specific lines of important recent research” culminating in current sophisticated document retrieval systems. I’ve ordered them by complexity:
- Representation learning (encoding queries and documents into vector representations)
- Neural-based re-ranking models (using neural-based models to score or rank documents
- Learning to rank (based on large volumes of easily accessible user interaction data)
So where does TF-IDF sit in this structure?
Below the very bottom.
As the authors explain, the learning to rank movement “represented a transformational leap beyond traditional TF.IDF-based IR systems.”
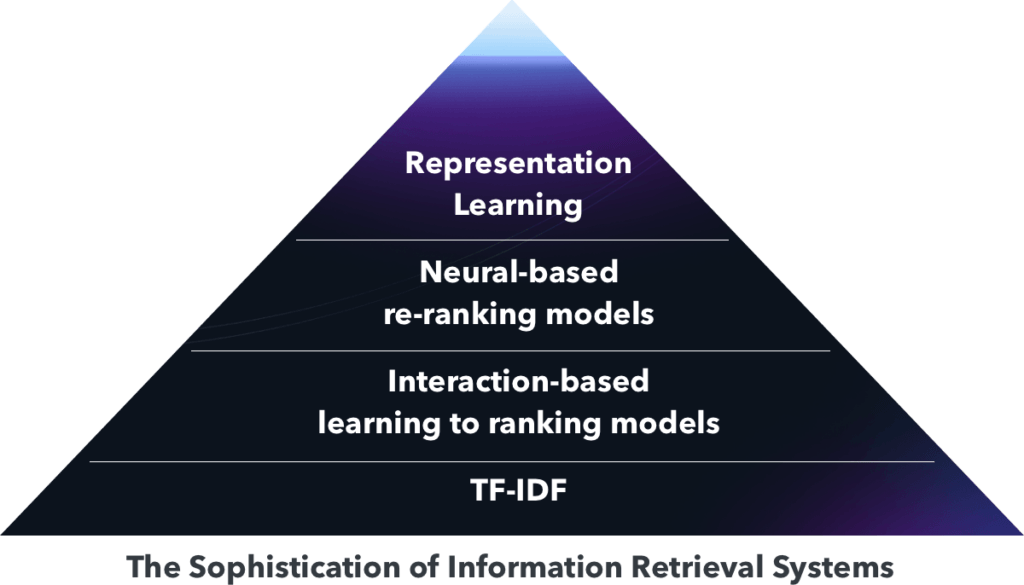
“Today’s state-of-the-art systems often rely on a combination of term-based (i.e., retrieval over an inverted index) and semantic (i.e., retrieval over an index of dense vector representations) retrieval to generate an initial set of candidates. This set of candidates is then typically passed into one or more stages of re-ranking models, which are quite likely to be neural network-based learning-to-rank models.“
TF-IDF die-hards may hold on to hope with the assertion that using TF-IDF performs “moderately better than individual keyword usage.” After all, any boost is better than nothing, right?
I don’t think that’s the implication.
But if “many advanced textual analysis techniques use a version of TF-IDF as a base” as the Moz article states, then there must be some validity to using it, right?
That’s like saying the whale is a version of the Placozoa. Yes, both are marine, free-living multicellular organisms. But it’s a stretch of the imagination to consider them equivalent.
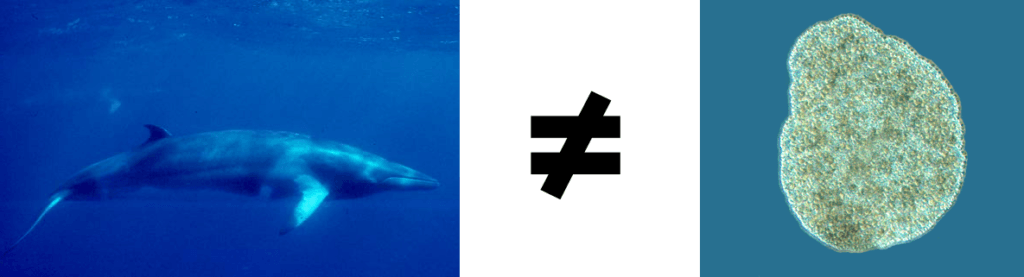
Keep in mind that the Moz article was published in 2014, which is anc
Here are some examples of neural-based re-ranking models against which you can compare TF-IDF:
PACRR: A Position-Aware Neural IR Model for Relevance Matching
End-to-End Neural Ad-hoc Ranking with Kernel Pooling
A Deep Relevance Matching Model for Ad-hoc Retrieval
As the Google researchers explain, “advanced machine learning and NLP-based approaches are an integral part of the indexing, retrieval, and ranking components of modern-day systems.” They don’t look anything like TF-IDF — not by a long shot.
The danger is that in associating TF-IDF with Google, some may assume that applying TF-IDF to their content creation process will guarantee they use the right words. The belief is that by using the correct words, they’ll rank higher.
That’s plain wrong.
I’m certain Google doesn’t use the TF-IDF algorithm in the way that proponents of TF-IDF tools would have you believe. You can understand why in a paper entitled Topic Models by David Blei and John Lafferty. Given that Blei is the one who first applied Latent Dirichlet Allocation (LDA) to machine learning, it’s one of the best references you can find.
“It is often computationally expensive to use the entire vocabulary. Choosing the top V words by TFIDF is an effective way to prune the vocabulary. This naturally prunes out stop words and other terms that provide little thematic content to the documents.”
They’re using the output from TF-IDF as an input to create a topic model. TF-IDF doesn’t generate the topic model itself. That’s a big difference!
So where’s the risk in using this type of tool?
You’re taking a shotgun approach. It’s like bringing a knife to a gunfight.
The danger is that, in trying to optimize content using this method, you end up alienating both readers and search engines. Remember when keyword density was all the rage among SEOs?

To this day, there are websites still paying for this misguided approach. Don’t let yours be one of them. Instead, create content from the perspective of information gain, adding something unique to the conversation surrounding that topic.
Although Google uses term frequency inverse document frequency, it only plays a role in text preprocessing. It doesn’t create the topic model itself. As a result, relying on the output of TF-IDF for content optimization is misguided.
Given the choice between optimizing content using TF-IDF or nothing at all, I’d choose the latter. Fortunately, you don’t have to.
If you’d like to learn how to create better content faster.
Visit our blog.
If you know another marketer who’d enjoy reading this page, share it with them via email, LinkedIn, Twitter, or Facebook.Stephen leads the content strategy blog for MarketMuse, an AI-powered Content Intelligence and Strategy Platform. You can connect with him on social or his personal blog.