AI Content Generation Comparison
While AI content won’t be taking over the internet anytime soon, I wanted to experience first hand what it was like creating content using AI. Specifically, I wanted to see the type of quality I could expect from the output of these four natural language generation models:
- GPT-2
- GROVER
- MarketMuse NLG Technology
- XLNet
So, I set out to create content, using those NLG models, on the following topics:
- Glucagon as a non-invasive diabetic treatment
- phone addiction
- how to grow peppers
- the power of storytelling
- how to become a substance abuse social worker
Then I evaluated each result against these criteria:
- MarketMuse Content Score (to determine how comprehensive the content is)
- MarketMuse Word Count (MarketMuse analyzes all the competitive content to determine how experts address a given topic)
- Grammarly Overall Score (to understand the amount of editing required to make the content publishable)
- Unique words (to measure vocabulary diversity)
- Rare words (to measure the depth of vocabulary)
- Word and sentence length (to evaluate the level of complexity)
- Flesch Reading-Ease (to determine if readability matched the intended audience)
Note that these are not language modeling benchmark upon which data scientists rely. Rather, they are real-world metrics that a content marketer would consider when evaluating a submission, whether human or not.
Summary of Results
Here are the results of running the five topics through four natural language generation models, plus some commentary.

MarketMuse Content Score
MarketMuse NLG Technology was the only model that was able to consistently meet or beat the Target Content Score. Our model is designed to generate output that is topically rich, comprehensive, and on-topic.
The other models? Apparently not so. In one case GPT-2 switched to another topic altogether, after which I terminated the output.
Have you ever met someone who likes to talk a lot but says very little of substance? Content Score is a way of measuring that. GROVER, GPT-2, and XLNet are the AI equivalent of that very person!
Word Count
MarketMuse NLG Technology was the only NLG model able to consistently generate content 1,000+ words in length. The other models struggled to produce anything beyond a few hundred words.
While GROVER would always generate a complete output of at least 500+ words, GPT-2 and XLNet were different. Occasionally XLNet was incapable of generating even 100 words. The output of GPT-2 and XLNet were terminated on occasions where there was a dramatic shift in topic or excessive repetition. In the case of repetition, I applied the ‘three strikes and you’re out’ rule.
Grammarly Overall Score
Grammarly’s Overall Score is a quick way of determining the level of editing required to turn a draft into a polished article fit for publication. Both MarketMuse NLG Technology and GROVER did quite well in achieving a high Overall Score, meaning the standard of writing was quite good with some basic editing required. GPT-2 and XLNet did not fare as well, especially considering their low word count. The output from these models would require significant editorial effort in order to be presentable.
Unique Words
GROVER consistently performed best at employing a varied vocabulary. Unfortunately, it did not translate into detailed discussions on any of the topics, as shown by its low Content Scores.
Rare Words
MarketMuse NLG Technology has a comparatively deep vocabulary, as shown by its high percentage of rare words across all topics. Note that all topic models operated below the average for all Grammarly users when looking at the percentage of unique and rare words.
Word and Sentence Length
MarketMuse NLG Technology and GROVER tend to use vocabulary with longer words than GPT-2 or XLNet. Across all topics, MarketMuse NLG Technology consistently used the shortest sentences. GPT-2, with only one exception, used significantly longer sentences thereby creating the potential need for additional editorial effort.
Flesch Reading-Ease
Flesch Reading-Ease is calculated such that content with higher scores is deemed easier to read. One needs to be careful when incorporating this metric as easier is not necessarily better. There are many challenges with applying Flesch Reading-Ease but in this case, I was looking to see whether readability was appropriate for the intended audience.
Take for example the topic Glucagon as a non-invasive diabetic treatment. I would expect the audience for this topic to have a college education and create content for that reading level. On the other hand, how to grow peppers is a topic appropriate for a wider audience. As such, the content should be easier to read. Other than a few odd exceptions, this is generally what happened.
Background on Natural Language Generation Models
Here’s some background information on the four NLG models used in this study and why they were chosen.
MarketMuse NLG Technology
MarketMuse NLG Technology (coming soon) is an NLG model that produces long-form content (1,000+ words) to a set of specifications. It maintains a narrative without templates or plagiarism while complying and validating with other metrics within an associated content brief.
The content brief (click to see example) contains everything a writer needs to create a comprehensive article including the subheadings (for structure), questions to ask, and topics to address. The same content brief is supplied to our natural language generation model to create an initial draft.
This explicit direction gives MarketMuse NLG Technology an inherent advantage over other NLG models which offer very little if any control. Think of it this way. Human writers rarely produce stellar work without any direction. Why would you expect something different from AI?
For this study, I managed to snag some samples from our data science team, unbeknownst to them!
GROVER
GROVER is a popular NLG model released in 2019 by Allen Institute for AI. It’s no longer publicly accessible, although it was when this post was originally written in May, 2020.
Having received quite a bit of press since its introduction to the public, I felt it would be a good model against which to compare. It was also the first model to introduce conditioning (control over generations). In this case, you can give your article criteria against which to write (domain, author, and headline) thereby giving some control over the final output.
GPT-2
GPT-2 was released in stages throughout 2019 starting with their smallest model. Major news outlets ran with this story and had a field day with it. The articles made it seem like GPT-2 output was indistinguishable from human writing.
HuggingFace offers a public-facing implementation of the model that I used for this study. According to the site, GPT-2 “currently stands as the most syntactically coherent model.” But honestly, I wasn’t impressed with its output.
I went with the default settings (large model size, Top-p 0.9, Temperature 1, Max time 1) because I figured it was the safest bet. I provided it with starting text in the form of a paragraph from the #1 article on the web, according to Google.
The way it works is that you provide a snippet of text (a sentence or paragraph) and it offers up to three choices for the next set of words (maximum of three words). For my test, I always selected the first choice, assuming that the first is the best and to be consistent.
I found this form of micromanaging is very tedious and the control that’s available to a user isn’t very helpful. It’s like trying to steer a car speeding down the highway looking at only the first couple of feet ahead.
One disturbing result is that the lack of higher-order structure can result in subject matter changing mid-article. One minute you’re talking about growing peppers and the next it’s about peaches!
XLNet
XLNet is an improvement of the state-of-the-art autoregressive model known as TransformerXL and outperforms BERT on 20 different tasks. Like GPT-2, it’s available for public use on HuggingFace. It also takes the same approach as GPT-2 on the question of control and suffers from the same issues.
Using These Natural Language Generation Models
What’s it like to use the NLG models? Here is what I found as I worked my way through this study. They’re organized by topic and NLG model.
Topic – Glucagon as a non-invasive diabetic treatment
MarketMuse NLG Technology
First, you need to create a Content Brief, just like you would if you were using a human writer. Once you’re satisfied with the Content Brief, you can request an initial draft. The generation process isn’t automatic. Presently, some human intervention is required, which is not surprising given that the service is not yet publicly available.

Notice the brief data appearing on the sidebar of this example? These are the questions and relevant topics which this section needs to address. This information guides the NLG process to ensure a favorable outcome. It met the Target Content Score of 38.
GROVER
GROVER was set to write against one of the top domains in the results for this topic and the author of that article. The hope here is that the output will emulate that style.
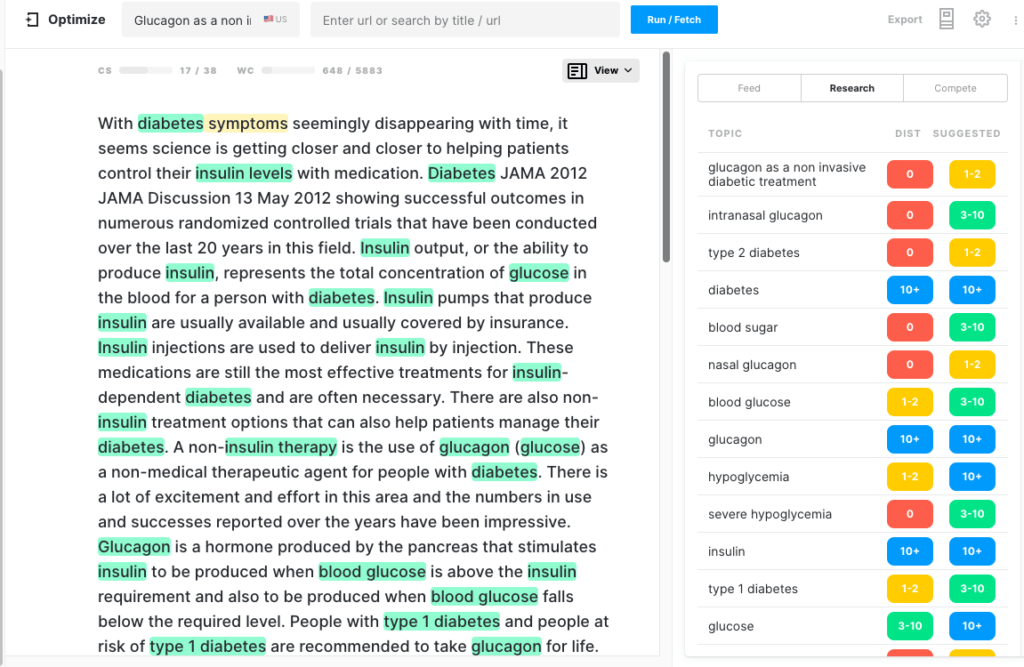
I tried three times and took the best generation which had a Content Score of 17. Although far better than GPT-2 and XLNet, with Content Scores of 0 and 4, it had nowhere near the substance of MarketMuseNLG Technology. It’s missing several key topics in its discussion of the subject.
GPT-2
I ran into a few problems using GPT-2 for this topic.
Only a few hundred words into the generation and it got “stuck” for lack of a better term. It kept on giving me only one choice for the next word in the article.


It also mislabelled T1D (a registry of people suffering from Type 1 diabetes) as a disease. Plus, the few hundred words it did generate resulted in a MarketMuse Content Score of zero.
Maybe there’s a problem with the GPT-2 model or the way it’s coded. But notice in the output the phrase “hyp” “oglyce” “mia”? This implementation of the model considers hypoglycemia to be three different words!
XLNet
Like GPT-2, XLNet also got stuck after just a couple of hundred words. It too suffered the wrath of the three-strikes rule (repeat something three times and it’s terminated). It fared slightly better in terms of Content Score (4), but that isn’t saying very much.

XLNet, like GPT-2, seems to have a similar problem. In this case, hypoglycemic is separated into three different words.
Topic – Phone addiction
MarketMuse NLG Technology
Here’s the beginning section of the output generated by MarketMuse NLG Technology.
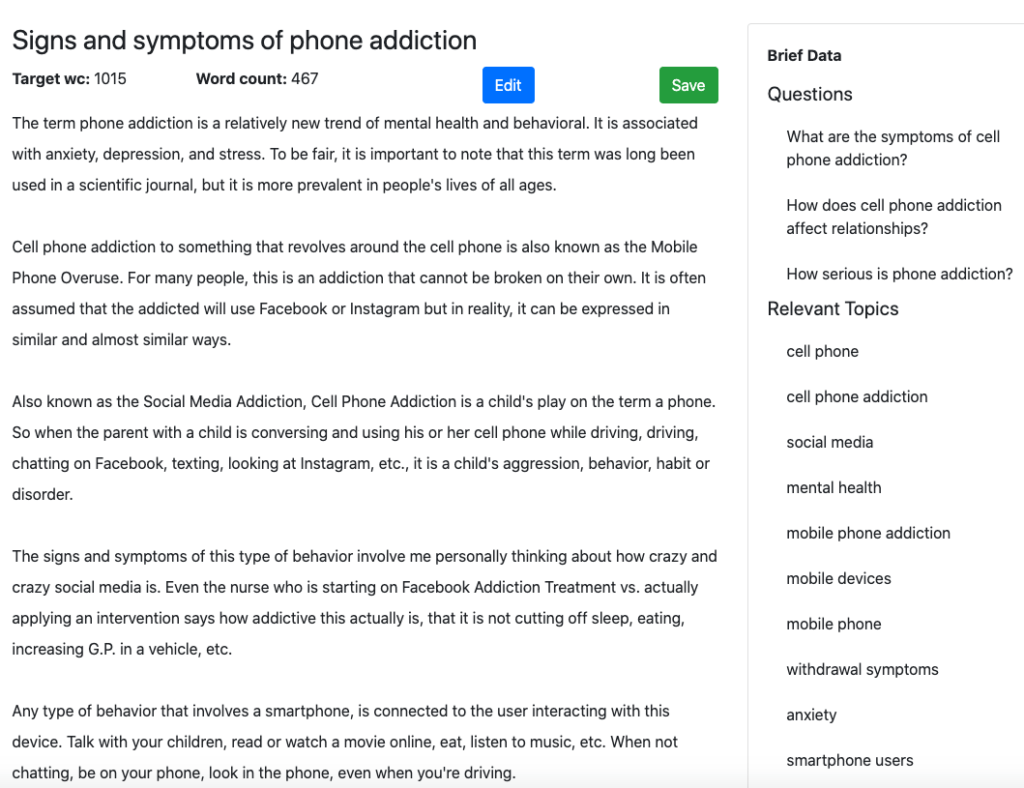
Here’s how it looks when in Optimize. Notice that it already has a healthy content score. Every highlighted topic is one that’s found in the model for that topic.

GROVER
I chose NYTimes and Nellie Bowels, an author who has written on this topic before, hoping that the generated text would come out looking impressive.
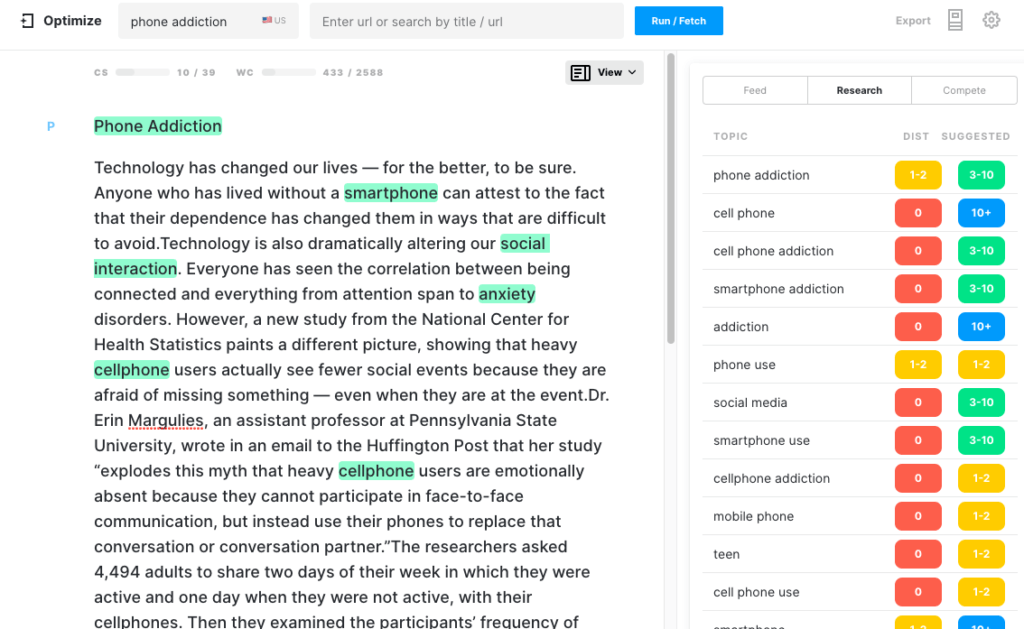
While it did achieve that objective, it’s rather vacuous when it comes to comprehensiveness. I tried multiple generations with the best being 431 words long with a Content Score of 7.
GPT-2
Started off talking about “phone addiction” and 500 words later the topic has changed to a review of an app that can control smart home devices!
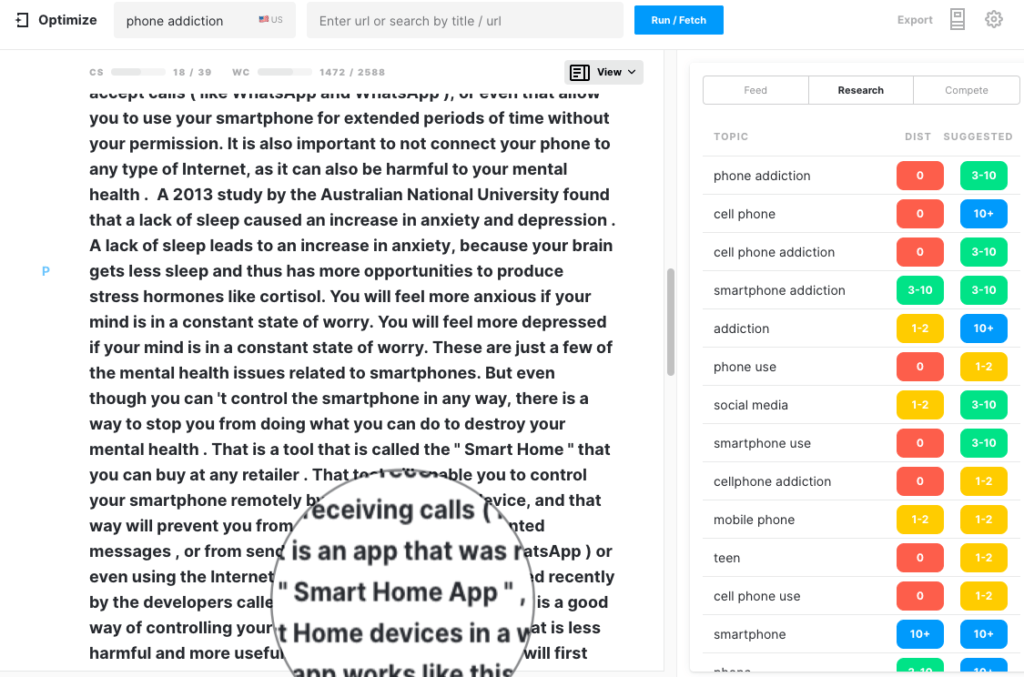
At this point, the article had a Content Score of 14 with a Target Content Score of 39. Since it was far from the target, I let the generation continue. At 1,048 words, the word count had doubled but the Content Score had increased slightly to 18. At 1,474 words the content score still had not changed. No surprise there since the generation had gone way off-topic.
XLNet
XLNet provided an experience similar to GPT-2. After about 300 words it got stuck in a loop and repeated itself. Three strikes and you’re out!

Topic – How to Grow Peppers
Admittedly, Glucagon is a pretty heavy topic. After something like that, growing peppers ought to be a walk in the park. Let’s find out.
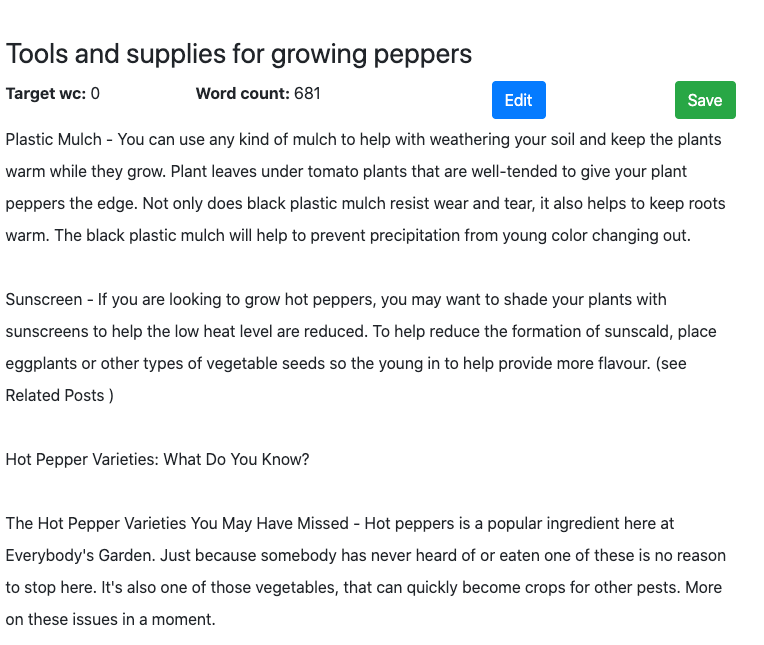
MarketMuse NLG Technology
Although MarketMuse NLG Technology hits all the metrics, its style of writing, in this case, leaves could be better. Oddly enough, its high Flesch Reading-Ease score indicates this article is easy to read.
GROVER
This generation was set to emulate the style of a popular author from TheSpruce who wrote a similar article that performs well in Search. At slightly over 600 words, it’s certainly doesn’t qualify as a treatise on the subject. It’s low Content Score confirms this.

GPT-2
Once again, this natural language generation model has trouble staying on-topic. Roughly 400 words into the generation and the article has shifted from talking about peppers to peaches! It was at this point that I stopped the generation, as it was unlikely to reverse course. It’s not surprising that it has such a low Content Score.

XLNet
There’s very little I can say about the text generation that XLNet provided for this topic. It got stuck after generating only one sentence! See for yourself. I gave it more than enough chances to correct itself after which I terminated the generation.

Topic – The Power of Storytelling
MarketMuse NLG Technology
If there was a topic where the story could go any which way, this would be it. But remember, MarketMuse NLG Technology is based on a highly structured Content Brief which is itself based on analysis of all the competitive content on that subject.
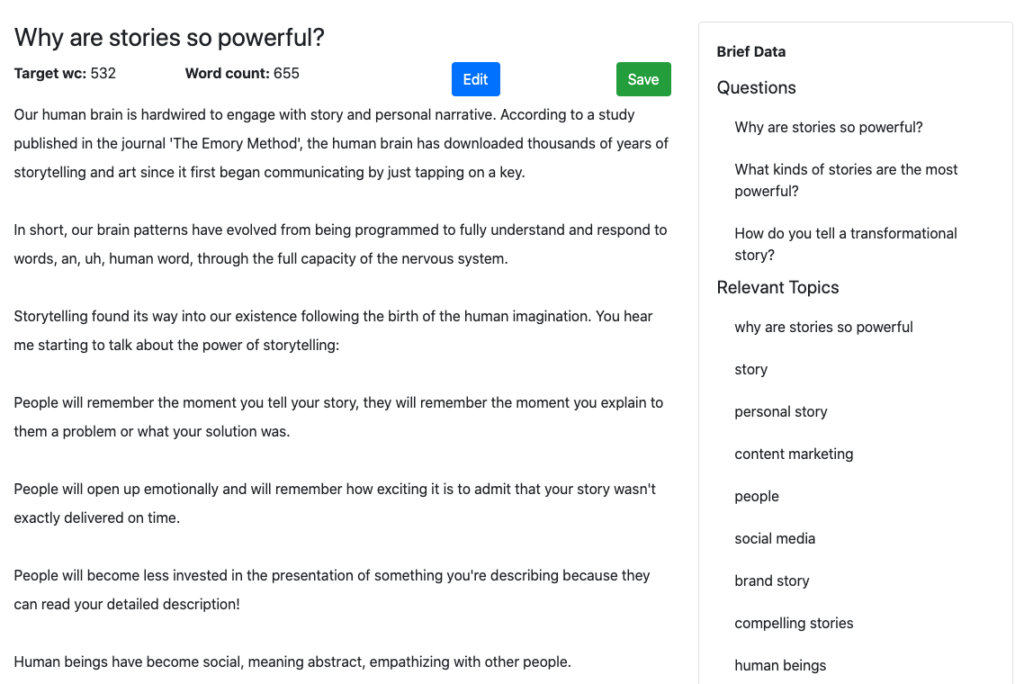
To rank well for this subject, there are specific topics you’ll need to cover. MarketMuse determines what those are.
GROVER
GROVER was set to write against one of the top 10 websites on this topic, health.org.uk. Once again the rationale was that emulating this prestigious publication would generate a credible article.
The result? Not really.
That’s not surprising when you think about it. With such little direction, what can you expect?
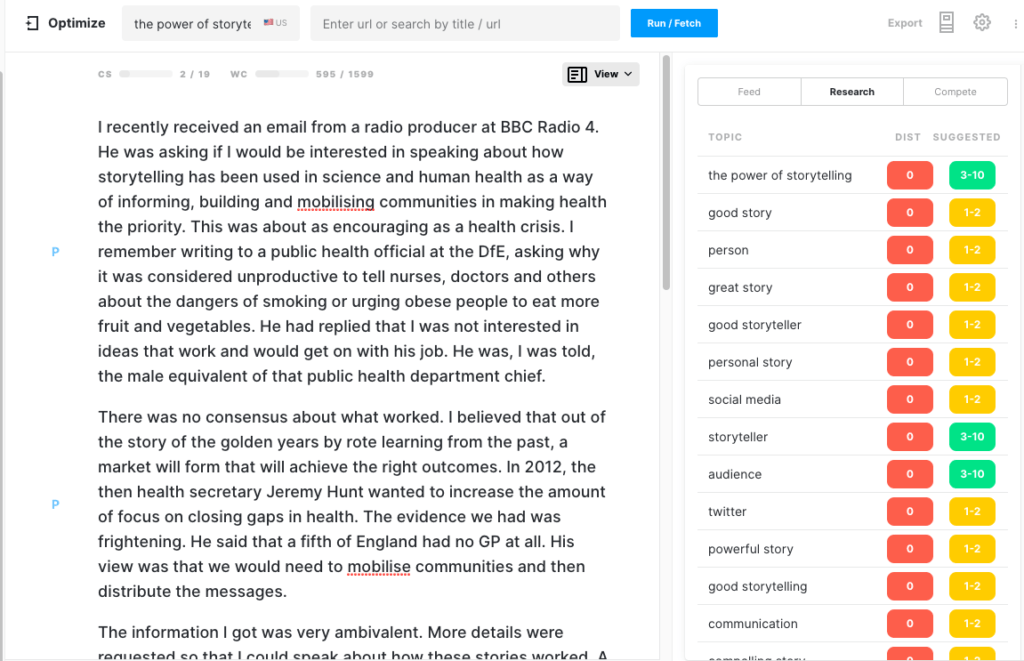
At 612 words, it was a short and mildly interesting story. But it wasn’t an article about the power of stories.
GPT-2
Once again, GPT-2 got stuck repeating itself, so I ended the generation. Most of the article is repetitive, resulting in low scores across all metrics.

XLNet
Like, GPT-2, I provided XLNet with the first paragraph from the high-ranking health.org.uk article on the same subject. The bold text is the material generated by the language model. Since it kept repeating the first sentence it created I ended the generation.

Topic – How to Become a Substance Abuse Social Worker
MarketMuse NLG Technology
I thought the topic was straightforward enough that all the models could excel in generating appropriate text. MarketMuse NLG Technology has the advantage of the Content Brief to provide structure, topics, and questions to address. What about the others?

GROVER
While GROVER can make up a story, it’s not always that informative. Granted, its Content Score of 16 far exceeds its rivals, GPT-2 and XLNet. However, it’s nowhere near that of MarketMuse NLG Technology at 36. Its relatively low Grammarly Overall Score 65 indicates there’s a fair amount of editing required to make it publishable.

GPT-2
This language model struggled to generate meaningful content on this topic. After the first 300 words, the text did not affect the Content Score, reaching a maximum of 7 versus a target of 31. Text quality diminished to the point where the output was no longer coherent so the generation was terminated.

XLNet
XLNet had the lowest Content Score (5) for this topic when compared to all four language generation models. Once again its output text had the smallest word count. Not only that but the text it created quickly degenerated into repetition upon which the generation was once more terminated.

Summary
In 2019, natural language generation models, GROVER and GPT-2 in particular, received a lot of attention. There was a fear that they could be used for nefarious purposes. The truth is that these models, unlike MarketMuse NLG Technology, struggle to generate long-form content that stays on topic and is comprehensive. This makes it challenging for content marketers to use them in any productive capacity.
There’s a fundamental difference in approach to natural language generation between MarketMuse NLG Technology and these models. In the case of MarketMuse NLG Technology, humans are tightly woven into the workflow and set the agenda for how the article is structured, the topics to discuss, and questions to answer. MarketMuse assists in determining what those items should be, but relies on human validation of these factors, prior to generating content. Our belief is that, in the current situation, AI works best for augmenting human writers.
If you’d like to learn how to create better content faster.
Visit our blog.
If you know another marketer who’d enjoy reading this page, share it with them via email, LinkedIn, Twitter, or Facebook.Stephen leads the content strategy blog for MarketMuse, an AI-powered Content Intelligence and Strategy Platform. You can connect with him on social or his personal blog.