Common Misconceptions About TF-IDF
Fifty years later and people still don’t understand Term Frequency Inverse Document Frequency (TF-IDF). Well, maybe I can help clear up some of the confusion. Here are five things you probably don’t know about TF-IDF but think you do.
1. TF-IDF is “an emerging technology.”
Nope. Not even close. In fact, it’s almost 50 years old! It’s based on the efforts of Hans Peter Luhn (1957) for his work on term frequency, and Karen Spärck Jones (1972) for her work on inverse document frequency. Only a dinosaur would consider half a century recent!
But to be fair, fifty years ago it was an emerging technology and an important advancement, just like Tony Hoare’s quicksort algorithm. Keep in mind that this is what a computer looked like back when TF-IDF was created.

We’ve made a few advancements since that time.
2. TF-IDF measures “how important a keyword phrase is by comparing it to that keyword’s frequency in a large set of documents.”
That’s both misguided and an over-simplification. Frequency does not imply importance (or more critically) semantic relevance. Also, IDF (Inverse Document Frequency) tries to dampen the influence of words occurring too frequently.
Let’s take a quick look at the difference between the output of a free TF-IDF tool and MarketMuse, which uses a more sophisticated approach. Let’s compare them for the term “starting a podcast.”
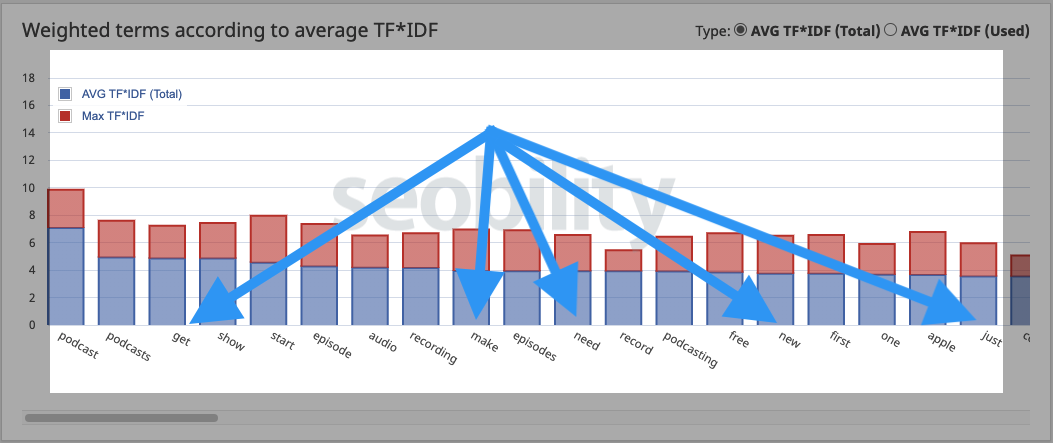
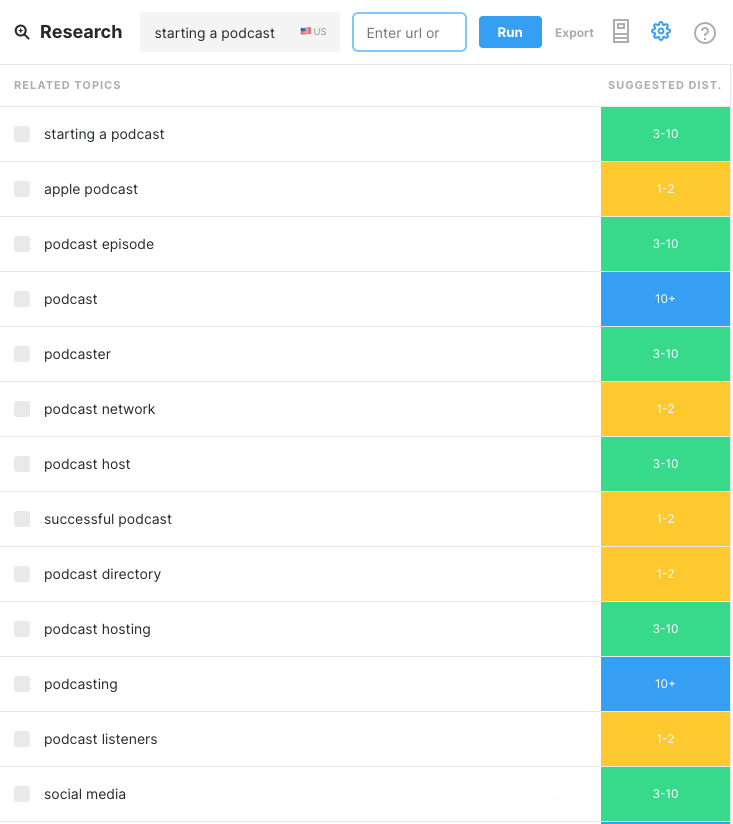
The output from MarketMuse is sorted by relevance with the most relevant appearing at the top. The number ranges refer to the distribution of mentions. Notice that topics mentioned frequently aren’t necessarily at the top of the list.
3. “It’s not yet clear if Google uses TF-IDF in its algorithm”
Well, that’s stating the obvious! Not to mention that Google doesn’t have AN algorithm. It has many algorithms, plural. TF-IDF can play an important part in that ensemble. For example, it’s an efficient method for stop-word removal. Those are words that frequently occur in human language but have little information value (e.g. and, or, but, the, a, an).
But, conceptually TF-IDF is a pretty simple mathematical formula. So debating whether Google uses TF-IDF is sort of like debating whether they use multiplication, division, addition, and subtraction. Its role, if any, will be minor.
4. “It’s a good practice to incorporate it into your on-page SEO strategy.”
No, it’s not. Not by a long shot. I’ve written about this before. Using TF-IDF may make you feel good but it’s misguided. See that comparison above if you’re still not clear on this.
5. “When you add these phrases and words to your content, it makes your article topically relevant and helps your page rank better in the SERPs.”
That is just wishful thinking. Using TF-IDF suggestions like “get, start, need, make, one, just, new” won’t make an article on starting a podcast more topically relevant; any more than using the terms “a, and, the, but” will.
And, you don’t need TF-IDF to tell you to use terms like “podcast, show, recording, episode, microphone.” If an article ranks better, it’s probably not from TF-IDF. Correlation is not causation.
Last Words
In the world of machine learning, text analysis, and topic modeling, TF-IDF is frequently mentioned because it’s a useful way of exploring a corpus and pre-processing text. In the world of SEO, that gets stretched into “making your page rank better in the SERPs.”
If you still have questions, take a look at this TF-IDF FAQ.
If you’d like to learn how to create better content faster.
Visit our blog.
If you know another marketer who’d enjoy reading this page, share it with them via email, LinkedIn, Twitter, or Facebook.Stephen leads the content strategy blog for MarketMuse, an AI-powered Content Intelligence and Strategy Platform. You can connect with him on social or his personal blog.