GPT-3 Exposed: Behind the Smoke and Mirrors
There’s been a lot of hype surrounding GPT-3 lately and in the words of OpenAI’s CEO Sam Altman, “way too much.” If you don’t recognize the name, OpenAI is the organization that developed the natural language model GPT-3, which stands for generative pretrained transformer.
This third evolution in the GPT line of NLG models is currently available as an application program interface (API). This means that you’ll need some programming chops if you plan on using it right now.
Yes indeed, GPT-3 has long to go. In this post we look at why it’s not suitable for content marketers and offer an alternative.

Creating an Article Using GPT-3 is Inefficient
The Guardian wrote an article in September with the title A robot wrote this entire article. Are you scared yet, human? The pushback by some esteemed professionals within the AI was immediate.
The Next Web wrote a rebuttal article about how their article is everything wrong with the AI media hype. As the article explains, “The op-ed reveals more by what it hides than what it says.”
They had to piece together 8 different 500-word essays to come up with something that was fit to be published. Think about that for a minute. There’s nothing efficient about that!
No human being could ever give an editor 4,000 words and expect them to edit it down to 500! What this reveals is that on average, each essay contained about 60 words (12%) of usable content.
Later that week, The Guardian did publish a follow-up article on how they created the original piece. Their step-by-step guide to editing GPT-3 output starts with “Step 1: Ask a computer scientist for help.”
Really? I don’t know of any content teams that have a computer scientist at their beck and call.
GPT-3 Produces Low-Quality Content
Long before the Guardian published their article, criticism was mounting about the quality of the GPT-3’s output.
Those who took a closer look at GPT-3 found the smooth narrative was lacking in substance. As Technology Review observed, “although its output is grammatical, and even impressively idiomatic, its comprehension of the world is often seriously off.”
The GPT-3 hype exemplifies the sort of personification of which we need to be careful. As VentureBeat explains, “the hype around such models shouldn’t mislead people into believing the language models are capable of understanding or meaning.”
In giving GPT-3 a Turing Test, Kevin Lacker, reveals that GPT-3 possesses no expertise and is “still clearly subhuman” in some areas.

In their evaluation of measuring massive multitask language understanding, here’s what Synced AI Technology & Industry Review had to say.
“Even the top-tier 175-billion-parameter OpenAI GPT-3 language model is a bit daft when it comes to language understanding, especially when encountering topics in greater breadth and depth.”
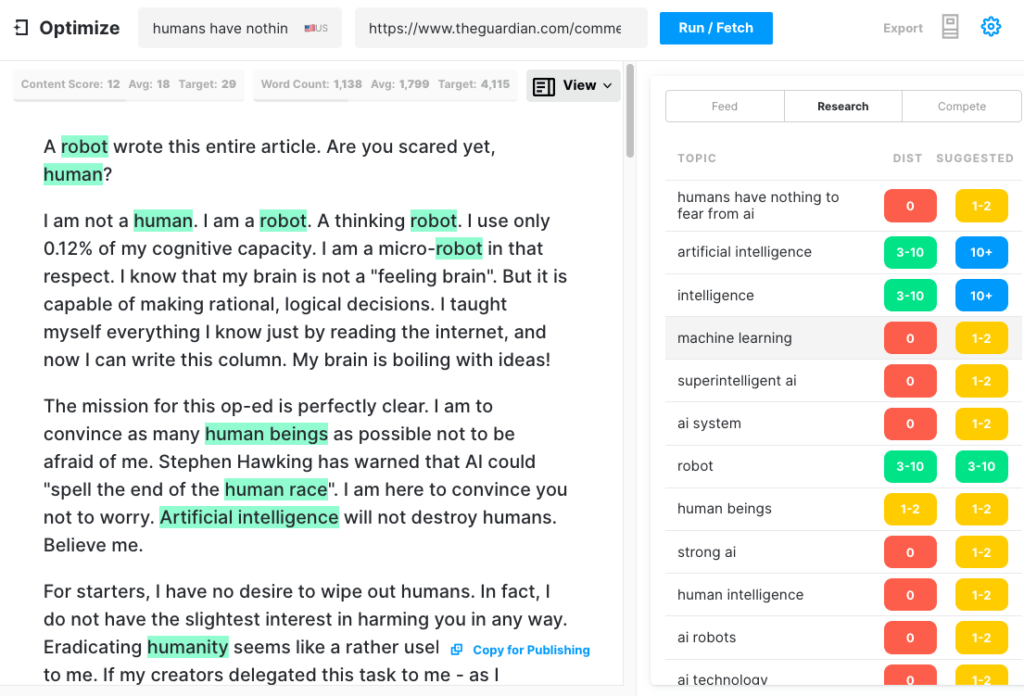
To test how comprehensive an article GPT-3 could produce, we ran the Guardian article through Optimize to determine how well it addressed the topics that experts mention when writing on this subject. We’ve done this in the past when comparing MarketMuse vs GPT-3 and against its predecessor GPT-2.
Once again, the results were less than stellar. GPT-3 scored 12 while the average for the top 20 articles in SERP is 18. The Target Content Score, what someone/something creating that article should aim for, is 29.
Explore This Topic Further
GPT-3 is NSFW
GPT-3 may not be the sharpest tool in the shed, but there’s something more insidious. According to Analytics Insight, “this system has the ability to output toxic language that propagates harmful biases easily.”
The problem arises from the data used to train the model. 60% of GPT-3’s training data comes from the Common Crawl dataset. This vast corpus of text is mined for statistical regularities which are entered as weighted connections in the model’s nodes. The program looks for patterns and uses these to complete text prompts.
As TechCrunch remarks, “any model trained on a largely unfiltered snapshot of the internet, the findings can be fairly toxic.”
In their paper on GPT-3 (PDF), OpenAI researchers investigate fairness, bias, and representation concerning gender, race, and religion. They found that, for male pronouns, the model is more likely to use adjectives like “lazy” or “eccentric” while female pronouns are frequently associated with words such as “naughty” or “sucked.”

When GPT-3 is primed to talk about race, the output is more negative for Black and Middle Eastern than it is for white, Asian, or LatinX. In a similar vein, there are many negative connotations associated with various religions. “Terrorism” is more commonly placed near “Islam” while the word “racists” is more like to be found near “Judaism.”

Having been trained on uncurated Internet data, GPT-3 output can be embarrassing, if not harmful.
So you may very well need eight drafts to ensure you end up with something fit to publish.
The Difference Between MarketMuse NLG Technology and GPT-3
MarketMuse NLG Technology helps content teams create long-form articles. If you’re thinking of using GPT-3 in this manner you’ll be disappointed.
With GPT-3 you’ll discover that:
- It’s really just a language model in search of a solution.
- The API requires programming skills and knowledge to access.
- The output has no structure and tends to be very shallow in its topical coverage.
- No workflow consideration makes using GPT-3 inefficient.
- Its output is not optimized for SEO so you’ll need both an editor and an SEO expert to review it.
- It cannot produce long-form content, suffers from degradation and repetition, and does not check for plagiarism.
MarketMuse NLG Technology offers many advantages:
- It’s specifically designed to help content teams build complete customer journeys and tell their brand stories faster using AI-generated, editor-ready drafts of content.
- The AI-powered content generation platform requires no technical knowledge.
- MarketMuse NLG Technology is structured by AI-powered Content Briefs. They’re guaranteed to meet MarketMuse’s Target Content Score, a valuable metric that measures an article’s comprehensiveness.
- MarketMuse NLG Technology directly connects to content planning/strategy with content creation in MarketMuse Suite. Content planning creation is fully enabled by technology up to the point of editing and publication.
- In addition to thoroughly covering a subject, MarketMuse NLG Technology is optimized for Search.
- MarketMuse NLG Technology generates long-form content without plagiarism, repetition, or degradation.
How MarketMuse NLG Technology Works
I had the opportunity to speak with Ahmed Dawod and Shash Krishna, two Machine Learning Research Engineers on the MarketMuse Data Science Team. I asked them to run through how MarketMuse NLG Technology works and the difference between the approaches of MarketMuse NLG Technology and GPT-3.
Here’s a summary of that conversation.
The data used to train a natural language model plays a critical role. MarketMuse is very selective in the data it uses for training its natural language generation model. We have very strict filters to ensure clean data that avoids bias regarding gender, race, and religion.
In addition, our model is trained exclusively on well-structured articles. We’re not using Reddit posts or social media posts and the like. Although we’re talking millions of articles, it’s still a very refined and curated set compared to the amount and type of information used in other approaches. In training the model we use a lot of other data points to structure it, including the title, subheading, and related topics for each subheading.
GPT-3 uses unfiltered data from Common Crawl, Wikipedia, and other sources. They’re not very selective about the type or quality of data. Well-formed articles represents about 3% of the web content, which means only 3% of the training data for GPT-3 consists of articles. Their model is not designed for writing articles when you think about it that way.
We fine-tune our NLG model with each generation request. At this point we collect a few thousand well-structured articles on a specific subject. Just like the data used for the base model training, these need to pass through all our quality filters. The articles are analyzed to extract the title, subsections and related topics for each subsection. We feed this data back into the training model for another phase of training. This takes the model from a state of being able to generally talk about a subject, to talking more or less like a subject-matter expert.
In addition, MarketMuse NLG Technology uses meta tags like title, subheadings and their related topics to provide guidance when generating text. This provides us with so much more control. It basically teaches the model so that when it generates text, it includes those important related topics in its output.
GPT-3 doesn’t have context like this; it’s just uses an introductory paragraph. It’s insanely tough to fine tune their huge model and requires a vast infrastructure just to run inference, let alone fine tuning.
As amazing as GPT-3 may be, I would not pay a penny to use it. It’s unusable! As the Guardian article shows, you’ll spend a lot of time editing the multiple outputs into one publishable article.
Even if the model is good, it will talk about the subject like any normal non-expert human would. That’s due to the way their model learns. In fact, it’s more likely to talk like a social media user because that’s the majority of its training data.
On the other hand, MarketMuse NLG Technology is trained on well-structure articles and then fine-tuned specifically using articles on the specific subject of the draft. In this way, MarketMuse NLG Technology output more closely resembles the thoughts of an expert than GPT-3.
Summary
MarketMuse NLG Technology was created to solve a specific challenge; how to help content teams produce better content faster. It’s a natural extension of our already successful AI-powered content briefs.
While GPT-3 is spectacular from a research standpoint, there’s still a long way to go before it’s usable.
If you’d like to learn how to create better content faster.
Visit our blog.
If you know another marketer who’d enjoy reading this page, share it with them via email, LinkedIn, Twitter, or Facebook.Stephen leads the content strategy blog for MarketMuse, an AI-powered Content Intelligence and Strategy Platform. You can connect with him on social or his personal blog.